서론
최근 진행했던 식도락 프로젝트에서 유저의 피드 목록을 페이징 처리를 하여 제공하는 api를 개발했습니다.
해당 api는 sns 특성상 페이지 단위로 제공하기보다는 무한 스크롤 형식에 최근 작성한 순서로 데이터를 제공해야 했습니다.
페이징 방식을 고민하던 중 offset과 no-offset 방식이 있고 offset 방식을 사용하면 매번 full-scan을 하여 성능적으로 좋지 않다는 것을 알게 되어 개발 당시에는 곧바로 no-offset 방식을 도입하여 개발하였습니다.
하지만 실제로 offset 방식과 no-offset 방식의 성능 차이가 얼마나 나는지 눈으로 확인하기 위해 두가지 방식을 모두 적용하여 성능을 비교해보기로 하였습니다.
offset이란?
offset 이란 sql에서 조회를 시작할 기준점을 의미합니다. limit은 조회할 결과의 개수를 의미합니다.
예를 들어 아래와 같은 쿼리가 있을 경우 5000번째 행부터 10개의 행을 읽겠다는 의미입니다. (이때 행은 0부터 시작합니다.)
SELECT *
FROM TABLE_NAME
LIMIT 10
OFFSET 5000;offset은 조회를 한 결과에서 limit으로 지정한 개수만큼만 반환하고 나머지는 버리는 방식으로 동작합니다. 위의 쿼리를 예로 들면 5000번째 데이터부터 10개를 조회하기 위해서는 5010개의 데이터를 모두 읽은 뒤, 앞의 필요하지 않은 5000개는 버려야합니다.
적은 양의 데이터를 조회할때는 성능적인 문제가 발생하지 않지만 전체 데이터의 개수가 많아질수록 앞에 읽어야하는 데이터의 양이 많아져 문제가 됩니다.
추가적으로 저는 offset 방식은 무한 스크롤에 적합하지 않다고 생각합니다.
유저가 피드를 조회한다고 가정하고 예를 들어 보겠습니다.
(데이터는 생성 순서대로 제공된다고 가정합니다.)
- 사용자가 1번~10번 리뷰를 조회했습니다.
- 이 시점에 새로운 데이터가 추가되었습니다.
- 11번~20번 리뷰를 이어서 조회합니다.
새로운 데이터가 추가 되었기 때문에 리뷰의 개수는 총 21개가 되며 기존 10번째 행에 있는 리뷰가 11번째 행으로 밀려나게 되고, 사용자는 원래대로 11~20번째 리뷰를 조회하게 됩니다. 여기서 문제가 발생하는데 offset 방식은 단순히 21개의 데이터 중 11~20번째 행을 결과로 반환할것입니다. 그러면 스크롤을 내리는 사용자의 화면에는 리뷰(기존 10번째 리뷰)가 중복되어 보이게 됩니다.
(물론 애플리케이션에서 추가적인 코드를 작성하여 해당 문제는 해결할 수 있겠지만 이것 자체가 비용이 발생하는것이고 곧 단점이라고 생각됩니다.)
위의 문제들을 해결하기 위해 저희 서비스에서는 no-offset방식을 적용하였습니다.
그렇다면 no-offset은 뭘까요?
이름 그대로 offset을 사용하지 않고 특정 id를 기준점으로 잡아 where절을 사용하여 데이터를 조회하는 방식입니다.
이 방식을 사용할 경우 기준점 이전의 데이터도 모두 조회하던 offset과 달리 기준점인 id부터 limit의 개수만 조회하기 때문에 데이터의 개수가 많아져도 성능문제가 발생하지 않습니다.
이어서 각각의 방식을 사용하여 실제 구현한 코드와 테스트를 통해 성능을 비교해보겠습니다.
동일한 환경으로 테스트를 진행했습니다.
[테스트 환경]
- 리뷰 데이터 : 10,000,000건
- 유저 데이터 : 1000명
- 테스트 시나리오 : 1번 유저가 999명을 팔로우하고 있으며, 1번 유저의 정보로 피드를 조회하도록 요청
(이때 조회할 데이터의 번호는 랜덤입니다.)
[offset 방식의 구현과 성능]
아래는 실제 저희 서비스에서 유저의 피드를 조회하는 메서드입니다.
메서드의 2번째 파라미터로 페이지 번호와 반환받을 데이터의 개수가 있는 Pageable 타입의 객체를 넘겨줍니다.

- 여기서 Pageable 인터페이스의 실제 구현체인 PageRequest 클래스를 사용하여 객체를 만듭니다.
- cursor가 페이지 번호, size가 limit을 의미합니다.

다음은 실제 나가는 쿼리입니다. 보시는바와 같이 offset이 적용되어 있습니다.
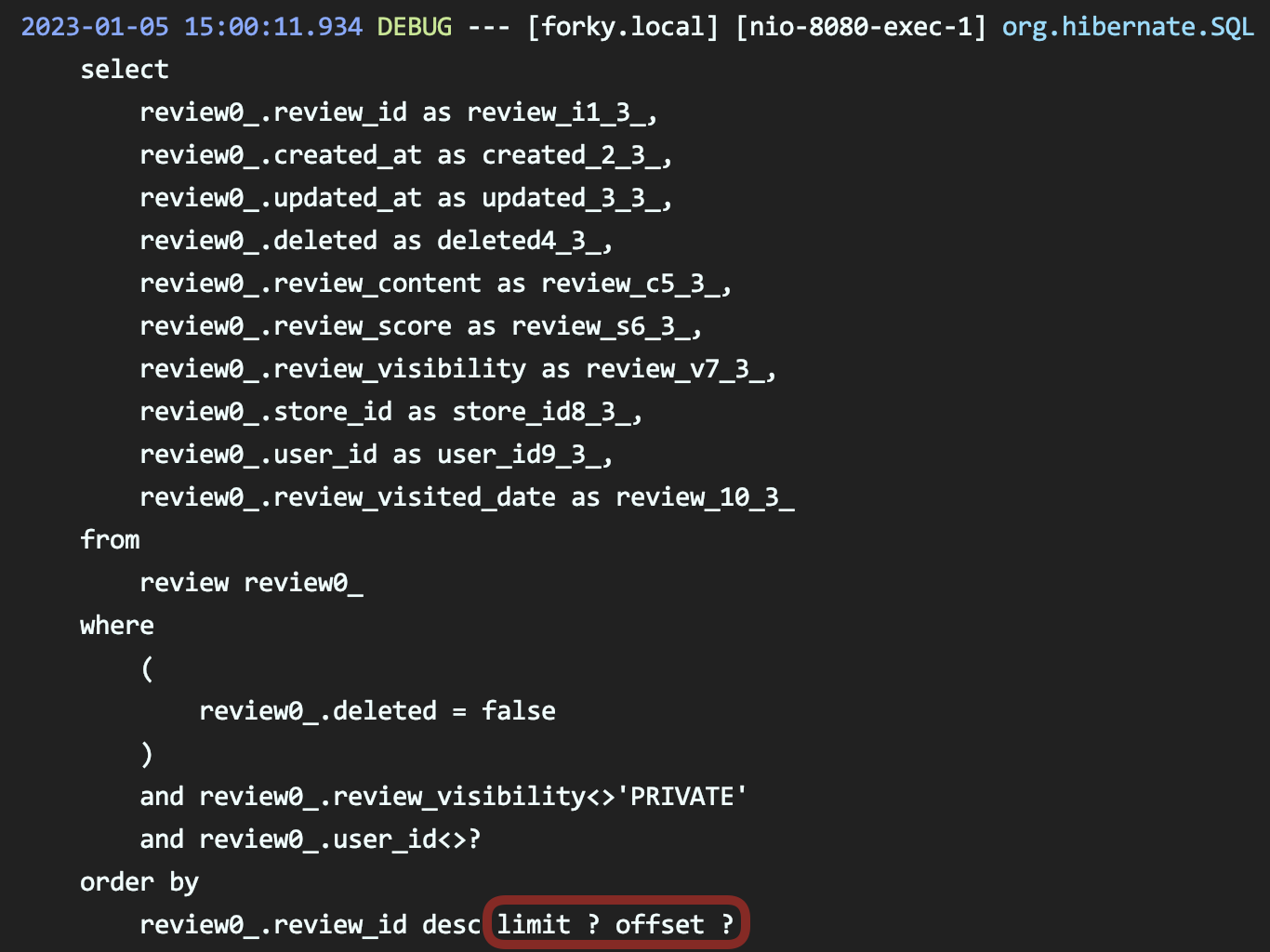
다음은 ngrinder를 사용하여 위에 적어둔 환경으로 3분간 테스트를 진행한 결과입니다.
- 초당 처리한 요청의 개수 : 1.5개
- 요청당 평균 응답 속도 : 약 31초
- 실패한 요청 개수 : 147개


많은 요청들이 위와 같이 Connection Pool로부터 커넥션을 가져오지 못해 ConnectionTimeout Exception이 발생하는것을 볼 수 있습니다.
다음으로는 no-offset 방식과 실제 테스트 결과를 보여드리겠습니다.
[no-offset 방식의 구현과 성능]
offset 방식의 메서드와 동일하지만 파라미터로 target id가 추가되었습니다.
(최신 데이터부터 반환해야되기 때문에 조건이 <=로 되어 있습니다.)

다음은 실제 실행되는 쿼리입니다.

- 여기서는 offset이 필요하지 않기 때문에 limit 역할을 하는 size만 Pageable 객체에 담습니다.
- 내부적으로는 PageRequest 구현체를 사용합니다.

아래는 동일한 환경에서 진행한 테스트를 결과입니다.
- 초당 처리한 요청의 개수 : 197개
- 요청당 평균 응답 속도 : 약 0.5초
- 실패한 요청 개수 : 0개

2가지 방식의 성능차이를 비교하면 아래와 같습니다.
- 초당 처리한 요청의 개수 : 1.5개 -> 197개 (32배 향상)
- 요청당 평균 응답 속도 : 약 31초 -> 약 0.5초 (60배 향상)
- 실패한 요청 개수 : 147개 -> 0
추가적으로 리뷰데이터 백만건을 가지고도 테스트를 진행해보았습니다.
- 초당 처리한 요청의 개수 : 12개 -> 214개 (17배 향상)
- 요청당 평균 응답 속도 : 약 8.3초 -> 약 0.48초 (16배 향상)
- 실패한 요청 개수 : 147개 -> 0

결과에서 알 수 있듯이 눈에 띄게 성능이 심하게 차이가 났으며 데이터가 많을수록 그 차이는 컸습니다.
한줄 마무리
직접 테스트를 진행한 덕분에 각 방식의 동작하는 과정과 성능적으로 얼마나 차이가 나는지에 대해 알 수 있었습니다.
하지만 결국 서비스의 특성에 맞춰 사용할 방식을 정하고 추후 성능을 개선하는것이 가장 좋은 해결책인것 같습니다.
feat. 성능비교 과정에서 고려하지 못한 점
최초 성능비교를 위한 테스트를 하는 시점에는 인메모리로 h2를 사용했습니다.
1. Out of Memory
[문제]
1,000,000건까지는 데이터가 잘 들어갔지만 10,000,000건부터는 OutOfMemory라는 에러메세지와 함께 데이터가 들어가지 않았습니다.
[해결]
H2 공식문서에서 찾아보니 Embedded 모드로 사용하면 실행하는 애플리케이션과 동일한 jvm 위에서 돌아간다는것을 알았습니다.
해결방법으로는 앱 실행 시 옵션을 줘서 최대 메모리 용량을 늘려주는 방법이 있었습니다. (jvm은 실행 시 기본적으로 최대 메모리 용량을 256mb로 설정한다고 합니다.)
하지만 매번 실행될때마다 데이터를 새로 넣는것은 비효율적일것 같아 로컬에서 도커 컨테이너로 mysql을 사용하도록 변경하였습니다.
2. 인메모리 DB와 도커의 성능 차이 (미해결..)
인메모리 DB를 사용하여 테스트할떄는 평균 응답속도가 4초~6가 나오는 반면 로컬에서 도커 컨테이너로 mysql을 띄우고 실행했을때는 0.5초밖에 걸리지 않았습니다. 당연히 메모리상의 DB가 더 빠른 성능을 보여줄것이라고 생각했지만.. 아무래도 같은 jvm 위에서 실행되며 해당 애플리케이션의 쓰레드를 통해 I/O 작업이 발생하기 때문에 부하가 많아질수록 DB 성능도 떨어지는게 아닐까라고 생각됩니다.
참고 자료